
How to train Large Language Models? - Part 1
Dataset Curation Strategies for Large Language Models

In our previous discussion, we talked about the circumstances that warrant training a model from scratch. Now, imagine embarking on the exciting journey of training a Large Language Model from the ground up. This post explores the basic principles of selecting and organizing datasets, which is the first and crucial step of training these amazing models. In the upcoming posts, we'll explore tokenizers, model architectures, objective functions, optimization methods, and how to increase the context length of the model.
These remarkable models possess the ability to absorb and comprehend vast amounts of information, enabling them to recall facts and engage in reasoning. Suppose we aim to create a language model specifically tailored to assist Indian Lawyers. To achieve this, our pretraining dataset should encompass a rich collection of law books, parliamentary acts, and court judgments. In a similar vein, when Bloomberg developed BloombergGPT, they curated a diverse dataset comprising financial documents and Internet data. Now let's delve into the fundamental principles of curating datasets for training these incredible models.
TL;DR:
Tokens are the atomic units of computation in Large Language Models (LLMs). They act as the essential building blocks that LLMs utilize to understand and manipulate text.
We should train the models for the maximum number of tokens possible, as long as the validation loss continues to decrease.
Including code in the dataset improves the performance of Large Language Models on reasoning tasks.
Deduplication may or may not be necessary depending on dataset quality, while training for multiple epochs can increase available tokens.
The DoReMi algorithm helps determine optimal sampling weights when working with multiple data sources, enhancing the robustness and versatility of large language models.
Tokens
When using the OpenAI API, you might have noticed that they charge based on the number of tokens in your prompt and the generated output. But what exactly are these tokens?
Unlike humans, artificial neural networks cannot read words in the same way. They need to convert words into numbers to make sense of them. This conversion is done by a tool called a Tokenizer. Tokenizers break down words into smaller parts called subwords and assign numbers to each subword. For example, the word "playing" might be broken down into subwords - "play" and "ing", with each subword assigned a unique number. In our next article, we'll delve into how to choose the right tokenizer for training a Large Language Model.
Think of tokens as the atomic units of reading for Large Language Models. They represent subwords that these models process and understand. The vocabulary of a model refers to the total number of distinct subwords it can comprehend.
How many Tokens do we need?
In 2020, Kaplan et. al. conducted a study on Large Language Models. They found that the model's performance depends more on its size and the number of tokens, rather than its specific architecture. They discovered a relationship between model performance, number of tokens, and model size, which can be described using power laws. To improve performance, they suggested scaling the model size and the number of tokens together. For instance, if the compute budget is increased by 100 times, they recommended increasing the model size by 25 times and the number of tokens by 4 times. During their experiments, they used the same learning rate schedules across all trials.
In 2022, Hoffman et. al. further explored the optimal learning rate schedule for training Large Language Models. They found that sticking to a fixed schedule is not the most effective approach. Instead, they suggested aligning the learning rate schedule with the number of tokens to achieve optimal performance. According to the updated scaling laws they proposed, if the compute budget increases by 100 times, it is advisable to increase both the model size and the number of tokens by 10 times.
While the aforementioned papers focused on determining the optimal model and dataset size for a fixed training compute budget, the Llama paper proposes a different approach focusing on practical applications. Instead of basing the model size and number of tokens on the training compute budget, it suggests to determine the model size based on the latency requirements of the production environment and to train the model using the maximum number of tokens feasible.1
Where do these tokens come from?
The training datasets provide the knowledge that we want to teach our models. Different models use different types of data for training. For example, BloombergGPT trains on domain-specific data and internet data, while models like Galactica and BioMedLM are trained only on domain-specific data. Deciding whether to mix domain-specific data with internet-scale data depends on the number of tokens available in the domain-specific data and the tasks we expect the model to perform.
There are some widely used datasets that are available to the public, such as:
Common Crawl / C4
Common Crawl is a non-profit organization that explores the web and offers free access to everyone. It provides valuable internet data with unnecessary code and non-text elements removed.
The C4 - Colossal Clean Crawled Corpus dataset is created from the Common Crawl dump of April 2019 and was specifically used to train T5 models. It is cleaner than the regular Common Crawl dump because it undergoes better filtering techniques like- removing pages which contain phrase ‘lorem ipsum”. 2The dataset has a size of 750 GB.
The PILE
The PILE is a dataset created by Eleuther AI, consisting of 22 different datasets with a total size of 825 GB. It includes filtered Common Crawl dumps, which make up 18% of the data, as well as other sources like ArXiv, Github, PubMed Central, the FreeLaw Project, and more. Models like OPT, GPT-J, and GPT-NeoX-20B have been trained on the PILE.
CarperAI is currently working on PILEv2, which will be an even larger and more diverse collection of around 40 datasets, mostly in English.
ROOTS
The ROOTS corpus, curated by the BigScience research initiative, is a collection of text sources focused on responsible open science and collaboration. It consists of 59 languages, including 46 natural languages and 13 programming languages. The dataset has a size of 1.6 TB and was used to train the BLOOM language model.
RedPajama
The Llama model was trained on a blend of different datasets, including Common Crawl, C4, Github, ArXiv, Wikipedia, Books, and Stack Exchange data. However, Meta, the organization behind Llama, did not release this dataset. In response, several research labs collaborated to recreate and openly share the same dataset. This dataset comprises approximately 1.2 trillion tokens and takes up around 5 TB of space when uncompressed.
Cerebras took the initiative to clean and remove duplicates from the RedPajama dataset. As a result, they created the SlimPajama dataset, which contains around 600 billion tokens and has a size of 2.5 TB when uncompressed.
RefinedWeb
The Technology Innovation Institute put together a massive dataset containing a staggering 5 trillion tokens. They accomplished this by carefully removing duplicate entries and filtering the data from Common Crawl dumps using techniques like fuzzy deduplication and heuristic filtering. From this extensive dataset, they have made 600 billion tokens publicly available. Moreover, they have trained Falcon models using this dataset.
The Stack
The BigCode project compiled a dataset known as The Stack, which includes more than 6TB of source code files. These files are from various programming languages and are licensed for permissive use. The Stack covers a total of 358 programming languages. Two code models, Replit-code-v1-3b and StarCoder, are trained using this dataset.
StarCoder's remarkable ability to perform well on reasoning tasks, even though it was primarily trained on code data, highlights the significance of training models with code to enhance their reasoning capabilities. This observation led Ofir Press, the creator of Alibi embeddings, to speculate that GPT-4 could potentially have been trained on extensive sources such as LibGen (consisting of over 4 million books), Sci-Hub (with over 80 million papers), and the entirety of Github.
To deduplicate or keep duplicates?
When curating the RefinedWeb dataset, the Technology Innovation Institute prioritized the removal of duplicate documents using the MinHashLSH algorithm. Similarly, Cerebras employed similar deduplication strategies for the SlimPajama dataset. It is widely acknowledged in research papers that major Large Language Models developed by Google, Deepmind, and Microsoft have exclusively been trained on deduplicated data. However, the question arises: is it necessary to remove duplicates, or can we train with them?
During the training of GPT-Neo-X-20B on the PILE dataset, researchers noticed that performance did not significantly diminish even without deduplication. To assess the impact of deduplication, EleutherAI researchers conducted experiments using two versions of Pythia models trained on the original and deduplicated PILE dataset. The results of their experiments shown in the following diagram revealed no clear advantage of deduplicating the dataset, as both variants of Pythia models performed similarly.

However, Anthropic conducted research that demonstrated a significant decline in performance when a small subset of data is repeated numerous times. For instance, they found that repeating only 0.1% of the data a hundred times (equivalent to 10% of the total tokens) resulted in the performance of an 800 million parameter model dropping to that of a 340 million parameter model. Another study, titled "Deduplicating Training Data Makes Language Models Better," revealed that models trained on the C4 dataset produced significantly less memorized text and potentially achieved higher accuracy at a faster pace.
With somewhat conflicting findings from different training experiments, Muennighoff and colleagues analyzed the effectiveness of deduplication on datasets such as OSCAR (noisier dataset) and C4 (cleaner dataset). They found that deduplicating OSCAR had a positive impact, while it had less influence on C4. Therefore, if we are confident in the quality of our dataset, we can commence training without deduplication. However, if there are concerns about the dataset's quality, it may be advisable to remove duplicates before training.
Training for multiple epochs?
Most modern Large Language Models are typically trained for a single epoch, meaning they go through the training data once. However, GPT-Neo-X-20B was trained for two epochs, and Galactica was trained for four epochs, without any negative impact on performance. This raises the question of whether we can train our models for multiple epochs and consequently increase the number of available tokens.
To address this question, Muennighoff and colleagues conducted an analysis using GPT-2 architecture and tokenizer. They trained 400 models with a maximum size of 8.7 billion parameters and up to 900 billion tokens, using subsets of the C4 dataset. Based on their experience, they concluded that repeating the data for up to four epochs produces similar results as using new data. However, after the fourth epoch, the benefits of repeating the data start to diminish and eventually level off. Additionally, they found that doubling the number of tokens by adding an equal amount of code alongside natural language did not harm performance on natural language tasks and actually improved performance in a reasoning task.
How to sample multiple data sources?
When dealing with datasets such as the PILE or RedPajama that contain multiple data sources, there is no set rule for determining the amount of data to sample from each source. Instead, these decisions are typically guided by heuristics or practical considerations. Certain models, like Palm and Glam, adapt the sampling frequencies of different data sources based on the specific downstream tasks. However, this approach necessitates training numerous models, and can lead to the model being too specialized and only performing well on a specific set of tasks.
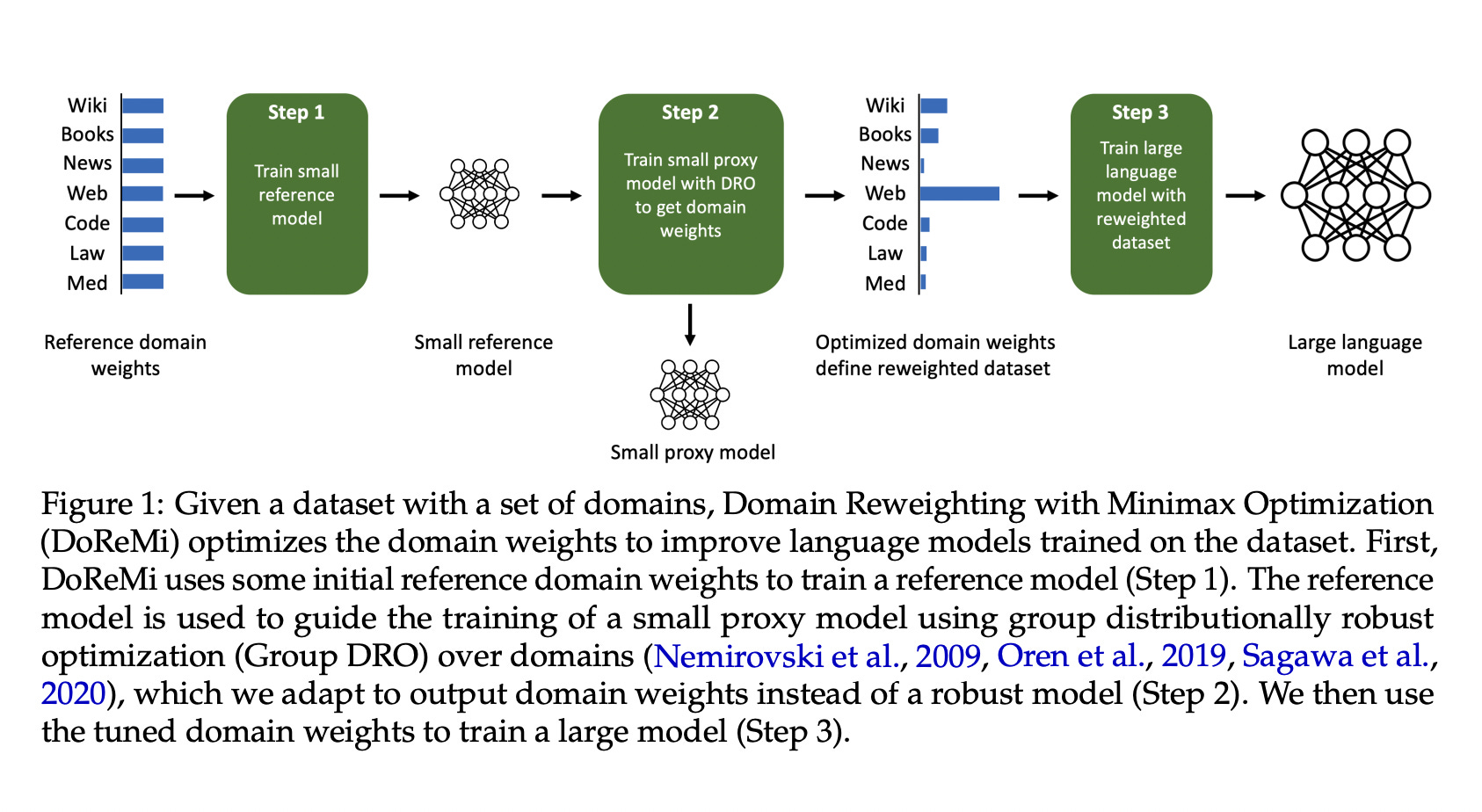
To determine the sampling weights when working with multiple data sources, the DoReMi algorithm employs a technique called Distributionally Robust Optimization (DRO). This algorithm does not consider the downstream tasks but focuses on finding the optimal sampling weights for each data source. In the first stage of DoReMi, a small reference language model is trained. Then, in the second stage, a distributionally robust language model is trained. This model aims to minimize the worst-case excess loss compared to the reference language model across all data sources or domains. Then we can extract the sampling weights from the DRO training. These sampling weights are then utilized to create the final dataset, which is subsequently used to train the large language model.
In conclusion, training Large Language Models from scratch offers an exciting opportunity to create models with exceptional capabilities. By curating domain-specific datasets and understanding the importance of tokens - numbers and sources, we can train powerful models tailored to specific domains and tasks. The number of tokens and model size impact performance, and aligning learning rate schedules with the number of tokens optimizes training outcomes. While the need for deduplication depends on dataset quality, training for multiple epochs can increase available tokens. When dealing with multiple data sources, the DoReMi algorithm provides a means to determine optimal sampling weights, ensuring a robust and versatile large language model. These models have the potential to revolutionize various fields and aid in knowledge generation and decision-making processes.
Cheers,
Sachin
s16r.com
We should aim to train for the maximum number of tokens possible, as long as the validation loss continues to decrease. In most current model training runs, the loss does not reach a saturation point, indicating that further training can be beneficial for these models.
Lorem ipsum is a placeholder text and it doesn’t have any meaning.