


Should you train your chatGPT?
Fine-Tuning vs. Embeddings vs. Prompts vs. Training from Scratch: Unraveling the Paths to Train Your ChatGPT

It's only been six months since chatGPT made its debut, and it has completely transformed the world. People are comparing this breakthrough to game-changers like the iPhone, the Internet, the Printing Press, and even Fire. chatGPT has set a record for the fastest adoption rate, attracting a million users in just five days. As the popularity and practical applications of chatGPT continue to grow, many open-source communities and major companies are developing their own Large Language Models.1 In this blog post, we'll explore the reasons why training your own chatGPT from scratch is a worthwhile pursuit.
Throughout this article, we'll use the term "chatGPT" to refer to different versions of GPT3.5 and GPT4. When we say "your own chatGPT," we mean training a basic language model and then additional training with Reinforcement Learning. We'll explain this process in detail in the next section. The main difference between GPT3 and chatGPT is that while GPT3 served as a base language model, chatGPT has been further developed using supervised fine-tuning and reinforcement learning.
The simple process of training
Building a powerful AI model like chatGPT is akin to constructing a masterpiece painting.2 It begins with pretraining, where the model learns the intricacies of language, analogous to an artist's blank canvas absorbing various colors and shapes. In supervised finetuning, data curators act as instructors, refining the model's skills through carefully crafted prompt-response pairs, similar to an artist adding finer details to their work. Then comes Reinforcement Learning, where prompts are evaluated by curators, guiding the model's improvement and resembling an artist's exploration and adaptation based on critiques. This analogy highlights the iterative journey of training AI models, mirroring the artistic process of creating a remarkable masterpiece.

Pretraining
In this step, we train a large language model by combining vast public datasets (such as the PILE or RedPajama) with your own proprietary dataset. These datasets contain billions of words. We train a neural network to predict the next words in a sequence based on the previous words, enabling the model to grasp language patterns and encode world knowledge within its model weights.
Supervised Finetuning / Instruction Tuning
In the second step, we take the base language model trained in the previous step and employ data curators to write pairs of prompts and responses, ranging from thousands to hundreds of thousands. An example of prompt-response pair can be:

We use this dataset to further finetune our base language model.
Reinforcement Learning
Training with Reinforcement Learning is a crucial step to enhance the quality of our model's responses and minimize the generation of false or toxic information. One popular approach for training with reinforcement learning is called Reinforcement Learning with Human Feedback (RLHF). Following image demonstrates the quality improvement achieved with RLHF, specifically using the InstructGPT model as an example.

Let's explore how this method works:
Reward Modeling
We ask human contractors to generate a vast number of prompts, ranging from hundreds of thousands to millions. Using the fine-tuned model, we generate multiple responses for each prompt. It is crucial to have skilled data curators evaluate these responses and determine the superior one. Their expertise helps us identify the most appropriate and high-quality response. We use their judgments to train a binary classifier, which becomes our reward model for distinguishing superior responses.
Reinforcement Learning with Human Feedback
In this phase, we engage contractors to create tens of thousands of prompts. Our instruction-tuned model generates responses to these prompts, which are then evaluated by the reward model. The reward model rates the quality of the responses. These ratings, along with variants of the REINFORCE algorithm like PPO or A2C, are used to further finetune the instruction-tuned model.


Why isn’t there an API to finetune chatGPT?
OpenAI currently offers APIs for finetuning GPT3 models, enabling customization for specific use cases, gaining a competitive advantage, and allowing for shorter prompts. However, there has been no announcement regarding an API for finetuning chatGPT models. One speculated reason behind this absence could be the limited availability of GPUs. While that may be a contributing factor, I'd like to explore an alternative explanation.
When we finetune a base language model, the objective is to train the model to respond in a different format or style, rather than teaching it new knowledge. It's assumed that all the necessary knowledge is already encoded in the base model's weights. If we were to finetune the base language model with new information, the model might end up creating false information, a phenomenon known as "hallucinations."3 chatGPT has been trained on a vast amount of proprietary data, and it would be extremely challenging for developers outside of OpenAI to determine what knowledge is contained within chatGPT's weights and design their finetuning datasets to minimize the occurrence of hallucinations.
Moreover, chatGPT employs Reinforcement Learning during training to minimize hallucinations. So while OpenAI could potentially provide a Finetuning API, a Reinforcement Learning training API, and a detailed guide for developers to understand the knowledge embedded in chatGPT's weights, training and evaluating models using this pipeline is a complex task.4 Inexperienced developers might face high experimentation costs, leading to dissatisfaction. Additionally, customer finetuned versions of chatGPT could potentially exhibit issues like hallucinations and toxicity, which could harm OpenAI's reputation.
When to train your model
There are three main reasons why you might consider training or deploying your models:
Performance: The chatGPT variants may not perform well or provide reliable responses for your specific task. If you find that the existing models are not meeting your requirements or delivering accurate results, training your own model could be a solution.
Cost: If you anticipate a high volume of requests, using OpenAI's APIs might lead to substantial costs that could potentially strain your budget or even bankrupt your project. Training your own model can be a cost-effective alternative in such cases.
Control or Differentiation: There could be regulatory or business concerns that prevent you from sharing your proprietary data with external servers like those of OpenAI or Microsoft. Alternatively, your business strategy might revolve around having a private model that sets you apart from competitors. Training your own model allows you to have full control over your data and offers a unique selling point.

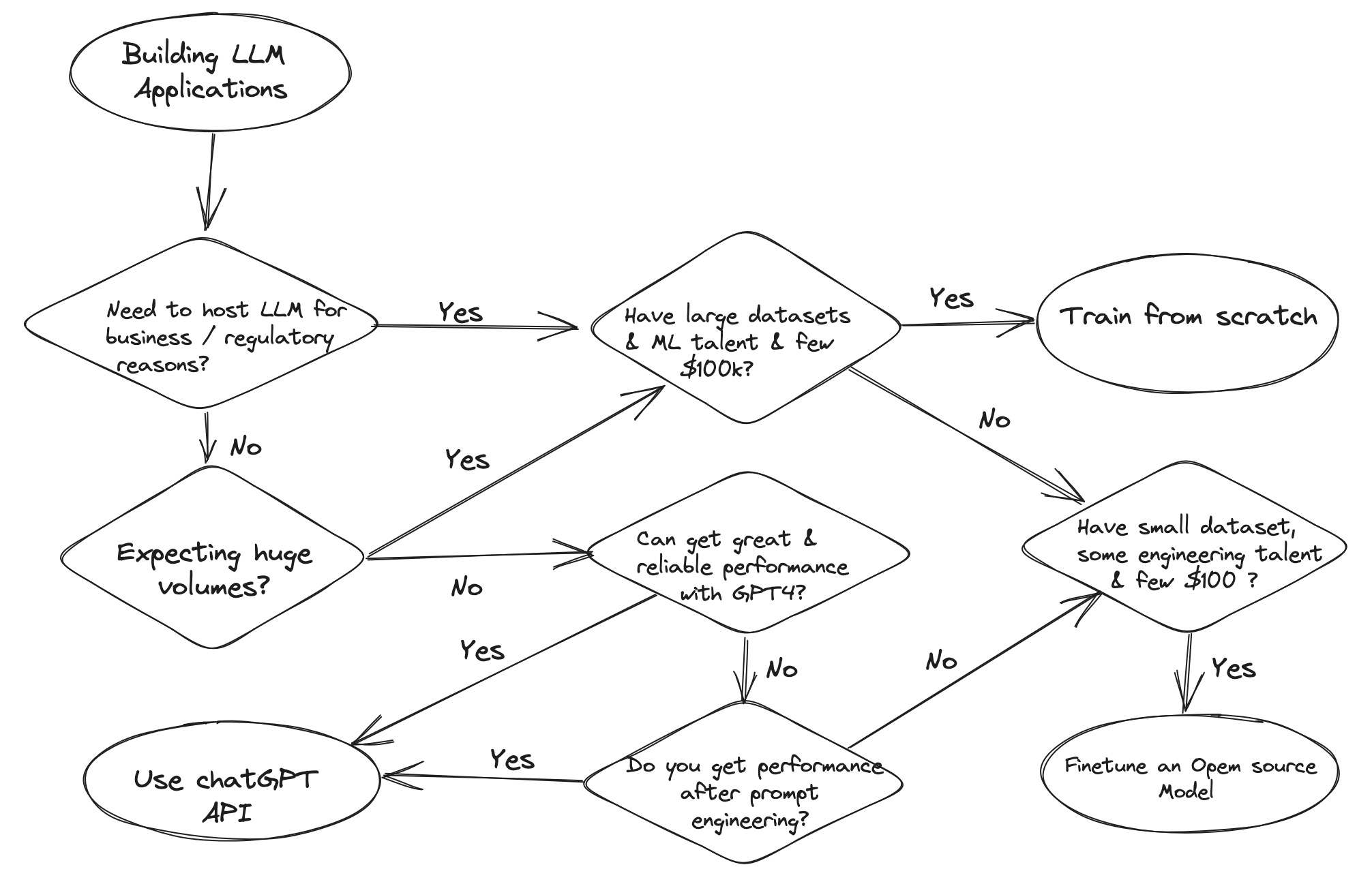
If the above reasons are not applicable to your situation, it is likely more beneficial for you to utilize the API provided by OpenAI or other language model providers.
If your main concern is performance, you can try employing clever prompting strategies or incorporating context into the prompt using embeddings. Since chatGPT has been trained on extensive amounts of data, it likely possesses the necessary underlying knowledge for your task. By using strategic prompts, you may be able to achieve good responses. According to Sam Altman, chatGPT can be seen as a reasoning engine rather than a direct source of knowledge. If we adopt this perspective, we can convey all the essential information to the model through the prompt using embeddings, which can significantly enhance its performance.
However, it's important to note that having the underlying knowledge within the model and allowing it to reason based on that knowledge is generally more advantageous than relying solely on passing the knowledge through the prompt.
If you still wish to deploy your own model, there are two alternatives:
Use an Open Source Model and Finetune / Train with Reinforcement Learning: You can start with an open source model and then finetune or train it further using reinforcement learning techniques. This approach offers relatively low compute costs (in the range of hundreds to thousands of dollars) and is relatively easy for your AI team to implement. You may need to hire contractors for data curation, but the expenses for this are usually much lower than the compute costs. Since the data sources of these models are also open source, you can gain an approximate understanding of the knowledge contained within the base language models.
Train your model from scratch.
If you have a large proprietary dataset, it might be more beneficial to train your own model from scratch and then apply finetuning and / or training with reinforcement learning. By controlling the dataset and training process, you can make specific choices to enhance performance and minimize costs.
Training the base language model can be quite expensive in terms of compute costs. For instance, training a single run of Llama 7B model could cost around $85,000 in compute expenses. Additionally, acquiring the necessary data can result in significant costs, potentially reaching millions of dollars, especially when dealing with domain-specific data that might be limited in availability. Training large language models from scratch is a complex task that requires deep expertise in model training, typically handled by skilled software engineers who command salaries exceeding $200,000. Consequently, the total cost to the company for pretraining can vary from around $200,000 if they possess in-house data and talent, to potentially a few million dollars if data acquisition and the hiring of skilled professionals is necessary. Nevertheless, the skill set required for training these models is becoming more accessible, with the availability of libraries and services5 that can support developers in training these models from scratch.
The costs associated with model training are expected to decrease in the upcoming months as the field continues to advance and new techniques are developed. This trend can make training large language models more accessible and cost-effective for organizations in the future.
The choice to train your own language model, be it through finetuning an open-source model or training from scratch, opens doors to endless possibilities. By harnessing the immense potential of AI, we have the opportunity to reshape society, explore the essence of humanity, and unravel the mysteries of intelligence. As costs decrease and accessibility improves, we are faced with a pivotal question: How will we wield this remarkable technology to shape our future? The answer lies in our hands and GPUs.
Cheers,
Sachin
s16r.com
Thanks to Nirant Kasliwal, Aditya Shastry, Sumod Mohan, Rohith Pesala, Ajay Deshpande and Srikanth Grandhe for reading the draft and giving detailed feedback.
Paul graham had compared the art of building software to the art of painting in his masterpiece - Hackers and Painters.
This information was first shared by John Schulman(11:35). Later it was empirically shown by Gudibande et.al.
OpenAI can provide finetuning API to their base models of GPT3.5 and GPT4. Also they are rumored to be experimenting to provide finetuning APIs for chatGPT variants as well.