


Finetuning Large Language Models
From Pretrained to Personalized Language Models

Three years ago, OpenAI introduced GPT-3, which caused a huge revolution in language technology and greatly impacted the machine learning community. GPT-3 demonstrated remarkable abilities in creating poems, captivating stories, and answering diverse questions with detailed responses. However, it had limitations and needed a new technique called prompt engineering to improve its results. Despite these challenges, GPT-3 gained immense attention and was considered a groundbreaking achievement, inspiring the creation of businesses like Jasper and copy.ai.

Around two and a half years after GPT-3 was launched, OpenAI introduced an amazing chat application called chatGPT. It was built using the same technology as GPT-3. This groundbreaking app quickly gained worldwide attention, with one million users trying it out in just five days. ChatGPT became the fastest-adopted application ever, impressing users with its clever and detailed responses to their questions.

The main difference between GPT-3 and chatGPT is how chatGPT is fine-tuned using supervised and reinforcement learning. This special tuning makes chatGPT better at satisfying users and improves overall performance. This improvement has made chatGPT a revolutionary language model application, changing how humans interact with computers.
Recipe for building chatGPT
In a previous article, we briefly covered three essential training steps for creating an application like chatGPT. Now, in this article, we will explore the finetuning process in-depth. If you're curious about pretraining, checkout these articles and stay tuned for the next ones in my series of articles dedicated to it, which might capture your interest.
Take a look at this image, depicting the distinct steps involved in training Llama 2-chat, and get a clear visual understanding of the process.

Pretraining : In this initial step, we train a neural network to predict upcoming words in a sequence based on the preceding ones. This process helps the model grasp the information within the text and create an internal representation of that knowledge. GPT-3 is an outstanding example of a pretrained language model.
Supervised Finetuning - SFT : In the following step, we take the pretrained language model and further finetune it using input and target pairs. This finetuning aids the model in understanding response styles, making it much more useful. However, solely performing this step can lead to the model generating made-up answers, also known as hallucinations.
Reinforcement Learning from Human Feedbcak - RLHF : In the final step, we take the model from the previous stage and finetune it to generate responses that users prefer. This step is critical for reducing hallucinations and ensuring the model produces more desirable outputs.
Supervised Finetuning - SFT
In this section, we will talk about how to create instruction or chat datasets, the technical details of implementation, memory complexity during the backward pass, and efficient tuning methods for parameters.
Datasets
For this step, we need to carefully select a large amount of input and target pairs to use for finetuning. To make the model more useful, we can use either open-source datasets like The Flan Collection, which has millions of samples, or a dataset like Dolly, created by Databricks employees, containing 15k samples. Additionally, there are methods like Evol-Instruct to automatically generate complex instructions, which are used for a group of improved language models known as wizard language models. A simple example of a supervised finetuning dataset can be as follows:
Inputs: Explain the moon landing to a six year old in few sentences.
Targets: Peoplewent to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.
However, if we want to use language models for chat applications, it's beneficial to create datasets that involve multi-turn conversations. In these datasets, both the user and the assistant take turns talking to each other. The LIMA paper demonstrated that having just 1k samples can be quite effective for finetuning. The Llama2 paper further supported this finding, revealing that after instruction tuning as explained in the previous paragraph, curating around 27k chat samples leads to strong performance. The OpenAssistant project contains many samples, out of which 10k are considered particularly robust.
OpenAI has introduced a format called chatML, which is becoming the industry standard for annotating conversations. This format is used to represent dialogue data in a standardized way. An example of a conversation using the chatML format is as follows:
Inputs:
[ {"token": "<|im_start|>"},
"system\nYou are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-01",
{"token": "<|im_end|>"}, "\n", {"token": "<|im_start|>"}, "user\nHow are you",
{"token": "<|im_end|>"}, "\n", {"token": "<|im_start|>"}, "assistant\nI am doing well!",
{"token": "<|im_end|>"}, "\n", {"token": "<|im_start|>"}, "user\nWhat’s your name?",
{"token": "<|im_end|>"}, "\n" ]Targets:
[ {"token": "<|im_start|>"},
"assistant\nI am chatGPT!",
{"token": "<|im_end|>"}, "\n" ]
Implementation details
In this notebook, we demonstrate a straightforward implementation of Supervised Finetuning. The notebook focuses on extracting the token ID from which the generation begins, and then it utilizes only the labels and logits from that token to compute the loss. If you wish to use this notebook as a reference, you can either develop your own PyTorch training loop, optimized for training, or leverage SFTrainer with DataCollatorForCompletionOnlyLM Collator.
Memory Complexity
Training is a memory-intensive process because the backward pass, used to calculate gradients, requires us to store gradients and optimizer states. When training in fp32, each parameter consumes 4 bytes for storage, gradients take 4 bytes, and optimizer states like copies of parameters, momentum, and variance for optimizers like AdamW consume 12 bytes. For a billion parameter model during finetuning, this means using 20 GBs just to store parameters, gradients, and optimizer states. If we have long sequence lengths or large batch sizes, we may encounter cuda out-of-memory errors, even on a 40GB A100 GPU.
To address these issues, we can implement mixed-precision training, store gradients in fp16, and use a memory-efficient optimizer like Adam8bit from bitsandbytes. Additionally, we can save significant memory by recomputing activations. For more in-depth information on how memory is utilized during training and inference with large language models, the Transformer Math 101 blog post by EleutherAI provides a detailed account.
Parameter Efficient FineTuning - PEFT
As the memory requirements for finetuning models are quite high, researchers have developed a few techniques to enhance model outputs without updating the model weights. One such technique is LoRA - Low Rank Adaptation, which finetunes a few extra parameters and then merges them with the original large language model. Another approach is the quantized version of LoRA - QLoRA, which backpropagates gradients through a frozen and 4-bit quantized version of the model to finetune Low Rank Adapters. Although these methods appear competitive with traditional finetuning, a more detailed analysis is needed to fully understand the exact trade-offs involved.
Reinforcement Learning
Reinforcement learning is a method where an agent learns to make decisions through trial and error. In this process, the agent interacts with an environment, and at each step, it observes a state, takes an action, and receives reward. The goal of the agent is to maximize the total reward it receives over time. To understand this concept, let's take the example of playing chess. The player is the agent, and the environment is the chessboard and the opponent's moves. At each moment during the game, the player observes the state of the chessboard, which is positions of the pieces on the chessboard. The action the player takes is the choice of which chess piece to move and where to move it. The reward is the outcome of the game, such as win, tie, stalemate or loss. The player's objective is to adjust their moves over time to strategize and win the game with their skillful gameplay.
Where does reward come from?
In the past, deep natural language systems like Google's Neural Machine Translation attempted to improve by finetuning neural networks with reinforcement learning, using BLEU score as the reward. However, they discovered that improvements in BLEU score didn't necessarily mean better results according to human evaluations.
In 2019, researchers at OpenAI found that getting feedback directly from humans, where they compared and ranked different outputs, led to better summaries. This specific form of human feedback was successfully used to finetune InstructGPT, and later helped make chatGPT more successful.
In 2022, Anthropic introduced the concept of Constitutional AI, where humans wrote rules that the Language Model must follow. They then iteratively asked the language model whether its generation followed the rules, and if not, how to improve. This type of feedback is called AI feedback and has the potential to complement human feedback in improving language models.
Reward Modeling
In this notebook, we showcase a simple way of implementing Reward Modeling. We assume that each token plays an equal role in improving the response and calculate the average reward score from the last hidden state responsible for each token. Another approach is to generate the reward using the last hidden state of the last generated token.
As you observe in the notebook, we use pairwise comparison loss and optimize it. However, if we carefully curate comparisons and train the network accordingly, we should notice a direct relationship between how humans rater responses and the reward score generated by the reward model.
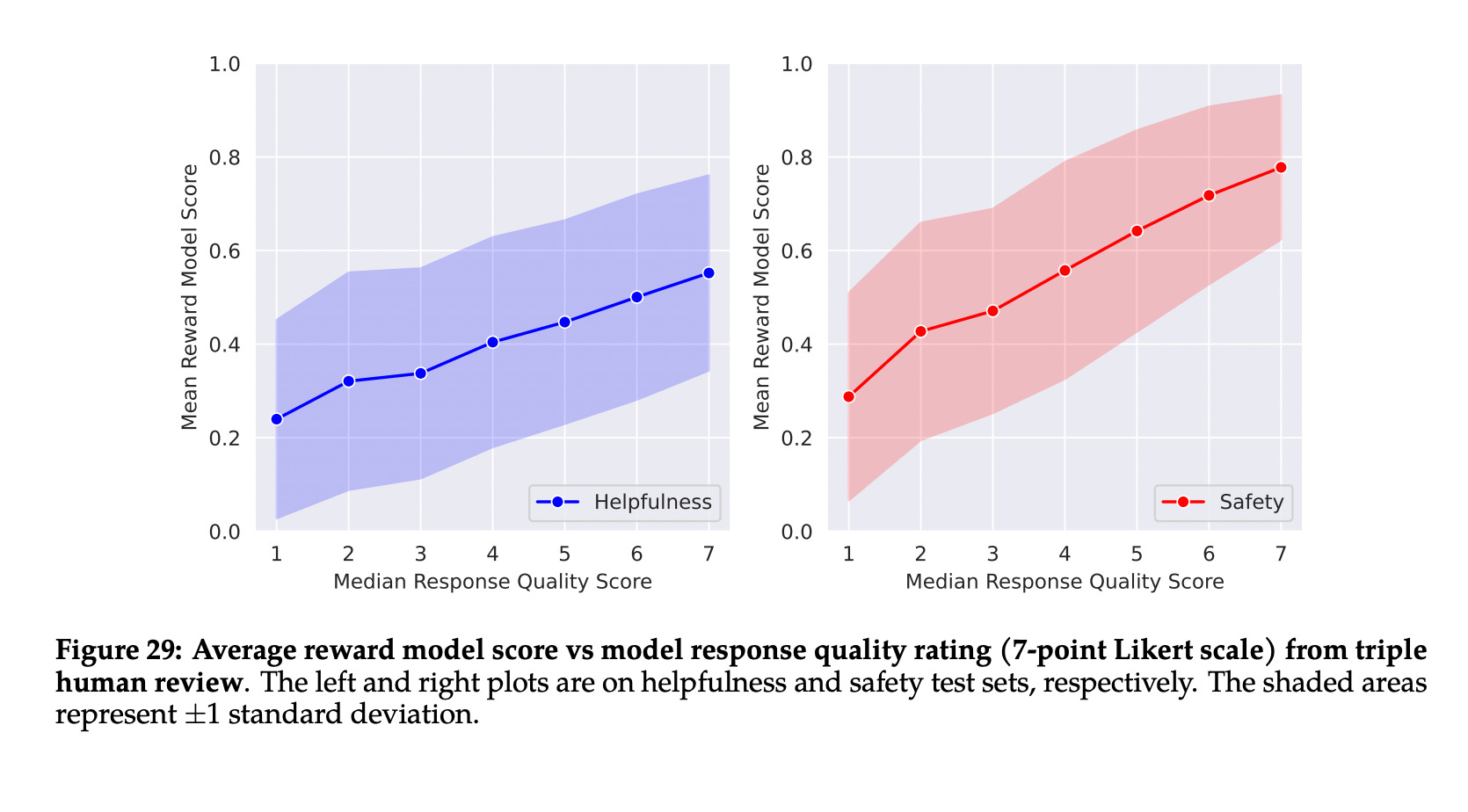
Sampling with Reward Models
Since reward models can determine which response is better, we can easily sample a few responses and let the reward model judge the best one. This approach, called Best of N sampling, can significantly enhance the model's performance without the need for Reinforcement Finetuning.
Another method to further improve the system is by curating a dataset of prompts and Best of N samples as targets and performing supervised finetuning on this dataset. This method is known as Rejection Sampling.
Reinforcement Learning methods
Reinforcement learning methods involve different approaches to guide agents in making decisions. Among them are model-based and model-free methods. Model-based methods rely on creating a model of the environment, helping the agent predict what will happen in the next state. In contrast, model-free methods directly learn from the environment without constructing a model.
Furthermore, reinforcement learning methods can be classified as value-based or policy-based. In value-based methods, the agent learns state-values - V(s) or state-action values - Q(s,a) , which represent the expected rewards in each state or state-action pair, respectively. For instance, V(s) can indicate how advantageous a particular chess position is, while Q(s,a) can provide insights into the expected rewards for specific moves in a given position. Advantage - A(s,a) quantifies how much better or worse the expected reward for a particular move (a) is compared to taking the usual action in that particular state. These value functions help the agent decide on the best actions to take in different situations. On the other hand, in policy-based methods, the agent learns the policy (π), which is a strategy for selecting actions in each state directly without predicting specific rewards.
One popular family of reinforcement learning methods that combines both policy and value learning is the actor-critic approach. The actor represents the policy and learns to choose actions, while the critic learns the value functions and estimates the expected rewards. By using this combination, the actor-critic method aims to improve the learning process and achieve better performance in various reinforcement learning tasks.
Policy Gradient Theorem
The policy gradient theorem provides us with an equation to update the policy parameters based on the gradients of the policy's expected rewards.

The equation involves ∇θ J(θ), which represents the gradient of the expected rewards J(θ) with respect to the policy parameters θ, and π(a|s, θ), which represents the policy's probability of taking action 'a' in state 's' given the policy parameters θ. The Q(s, a) is the Q-value, which estimates the expected rewards when taking action 'a' in state 's'. By using this equation, we can calculate the gradients of the log-probabilities of actions multiplied by the state-action values (Q-value) and use these gradients to update the policy parameters, thereby improving the agent's decision-making abilities.
If we substitute observed returns Gt in the above equation instead of Q(s, a), we get the REINFORCE algorithm. However, this algorithm can have high variance. To reduce the variance and improve the learning efficiency, we introduce a baseline, which estimates the expected rewards for different states. By subtracting the baseline from the actual rewards, we calculate the advantage, which indicates how much better or worse an action is compared to the expected rewards. This advantage is crucial for methods like Advantage Actor-Critic (A2C), where both the actor and critic work together to fine-tune the policy based on the advantage values.
Advantage Actor-Critic (A2C-RLHF)
In this notebook, we implement Advantage Actor-Critic (A2C) with Reward Model for Reinforcement Learning from Human Feedback. We still assume that each token plays an equal role and predict the state's value from the last hidden state of each prompt token.
Alternatives to using Reinforcement Learning methods
Reinforcement Learning methods can be difficult to implement and sometimes unstable during training. To address these challenges, Zhao et. al. proposed the use of ranking calibration loss on human feedback data. This method is similar to rejection sampling, where we train the model to increase the likelihood of selected responses compared to the likelihood of rejected responses.
Another alternative to existing Reinforcement Learning methods is Direct Preference Optimization (DPO) method. With DPO, we increase the likelihood of preferred responses and decrease the likelihood of rejected responses based on the magnitude of error in their respective reward estimates. This method is claimed to be competitive with traditional Reinforcement Learning algorithms while being more stable and computationally lightweight. These alternatives offer promising ways to enhance the learning process and achieve better performance in various tasks.
Importance of Finetuning with Reinforcement Learning
With only supervised finetuning, the model's performance is restricted by the writing skills of the dataset annotators. However, by incorporating reinforcement learning, we can tap into the vast diversity of the internet to produce more varied responses. Annotators find it easier to rank responses rather than creating better ones.

In cases where the model lacks the answer to certain questions, supervised finetuning can lead the model to generate false information, known as hallucinations. To combat this, we can provide negative feedback for incorrect answers and encourage the model not to answer when unsure. This approach helps to significantly reduce model hallucinations and improves the overall reliability of the responses.
Conclusion
Fine-tuning large language models for our specific use cases is crucial to achieving an excellent product experience. Although supervised fine-tuning can greatly enhance the model's usability, it has the drawback of incentivizing the model to generate false information (hallucinate). However, by further fine-tuning the model using Reinforcement Learning, we can significantly improve its performance according to human raters and reduce instances of hallucinations. This combined approach allows us to create a more reliable and effective language model for various tasks and applications.
Cheers,
Sachin
s16r.com